基于ZK的Hadoop高可用环境搭建
撰写时间: 2021-12-10 总共: 16229 字 转载请注明: BY-SA 4.0(除特别声明或转载文章外)
环境配置
环境:Window10、VMware 16
安装镜像:CentOS-7-x86_64-DVD-1810.iso
配置软件源
安装wget
yum install -y wget
更换软件源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
配置静态ip
虚拟机网络配置
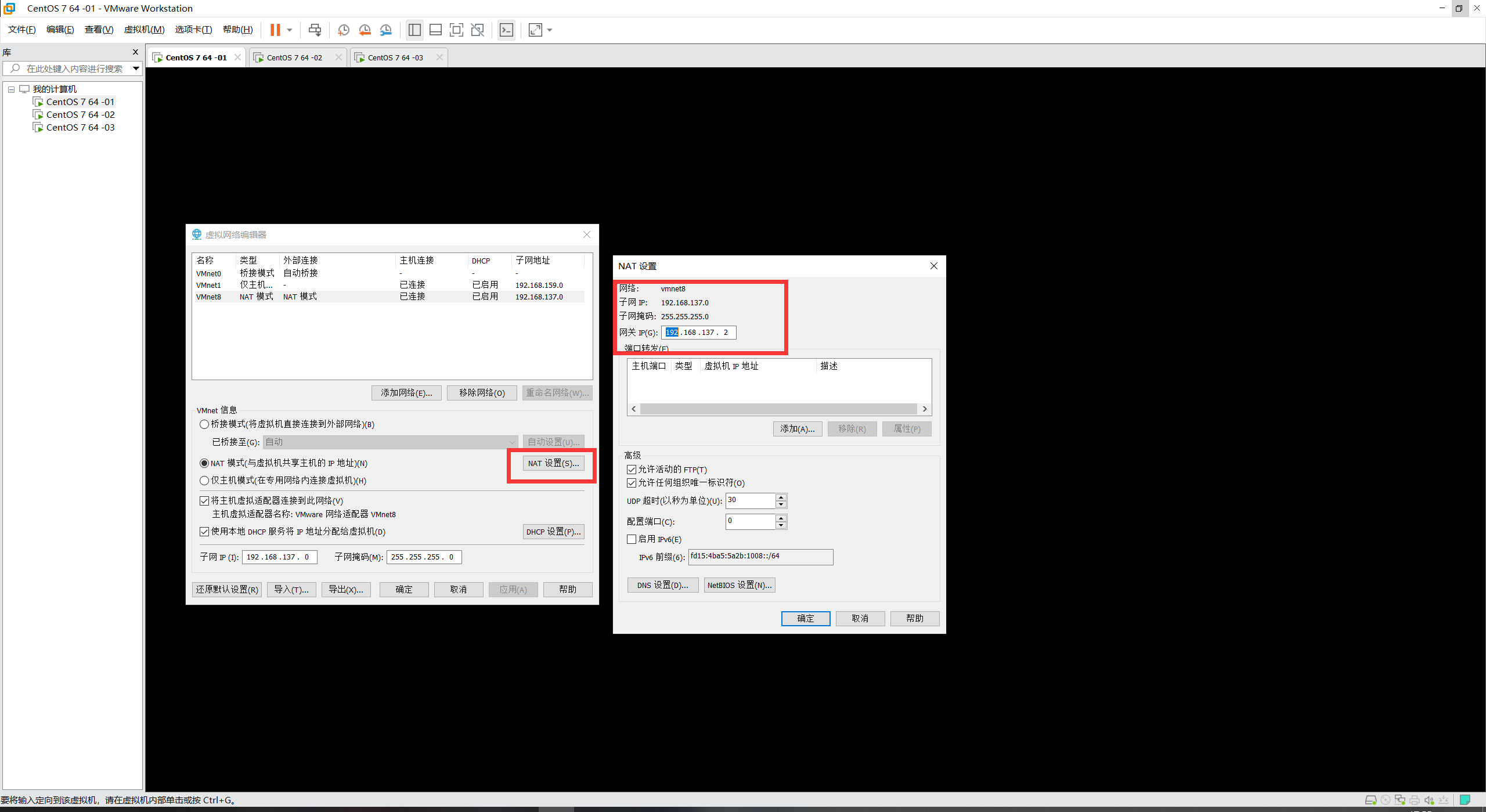
配置网络
1. 修改网卡配置
sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33
### ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
#BOOTPROTO="dhcp"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
#IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="be2adbbf-967e-4ab6-b33d-7e63b81c9ca3"
DEVICE="ens33"
#ONBOOT="yes"
## add static ip addr
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.137.10
NETMASK=255.255.255.0
GATEWAY=192.168.137.2
DNS=8.8.8.8
sudo vim /etc/sysconfig/network
sudo vim /etc/sysconfig/network
# Created by anaconda
NETWORKING=yes
GATEWAY=192.168.137.2
HOSTNAME=DEV01
sudo vim /etc/hosts
# add
192.168.137.10 DEV01
192.168.137.20 DEV02
192.168.137.30 DEV03
# 重启
reboot
2. DNS
sudo vim /etc/resolv.conf
## add
nameserver 8.8.8.8
3. 重启网络
service network restart
4. 配置环境变量
提前上传需要的软件压缩包,如:

解压安装后配置环境变量
sudo vim /etc/profile
# java env
export JAVA_HOME=/home/soft/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
# hadoop env
export HADOOP_HOME=/home/soft/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# zookeeper env
export ZK_HOME=/home/soft/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$PATH:$ZK_HOME/bin
# hbase env
export HBASE_HOME=/home/soft/hbase-2.2.4
export PATH=$PATH:$HBASE_HOME/bin
# 生效
source /etc/profile
5. 克隆2份虚拟机
克隆完毕后依次修改 IP 地址、刷新环境变量等。
可利用ssh 登录这3台虚拟机
# ssh
ssh root@192.168.137.10
ssh root@192.168.137.20
ssh root@192.168.137.30
后续修改环境变量后可使用scp将其分发到其他服务器
#source /etc/profile
[root@localhost soft]# scp /etc/profile root@192.168.137.30:/etc/
root@192.168.137.30's password:
profile 100% 2303 3.9MB/s 00:00
[root@localhost soft]# scp /etc/profile root@192.168.137.20:/etc/
root@192.168.137.20's password:
profile 100% 2303 1.6MB/s 00:00
[root@localhost soft]#
配置SSH免密
配置每台服务器之间的ssh免密
配置SSH
ssh-keygen -t rsa
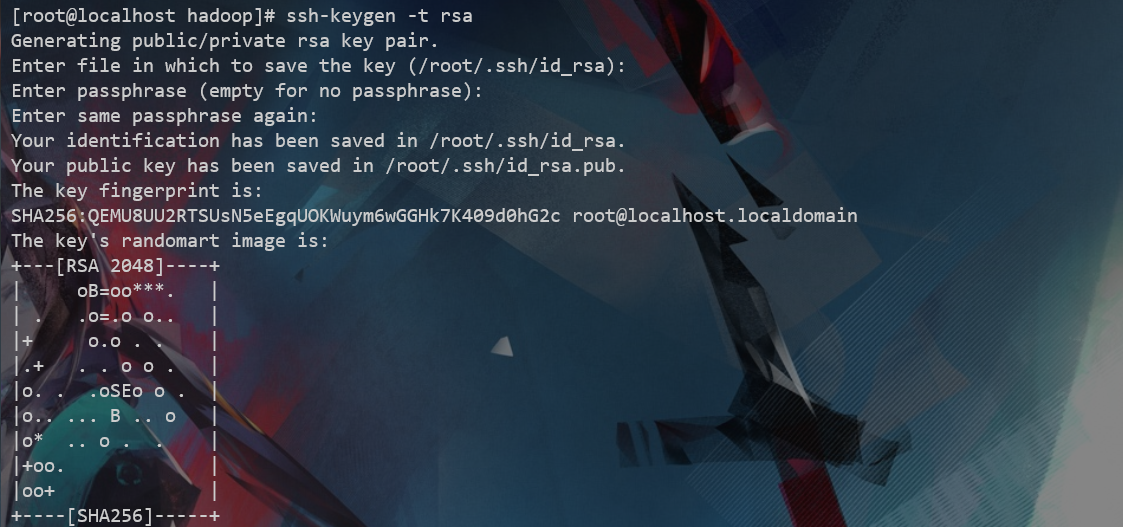
执行完这个命令后,会生成id_rsa(私钥)、id_rsa.pub(公钥),将公钥拷贝到DEV02\DEV03
# DEV01
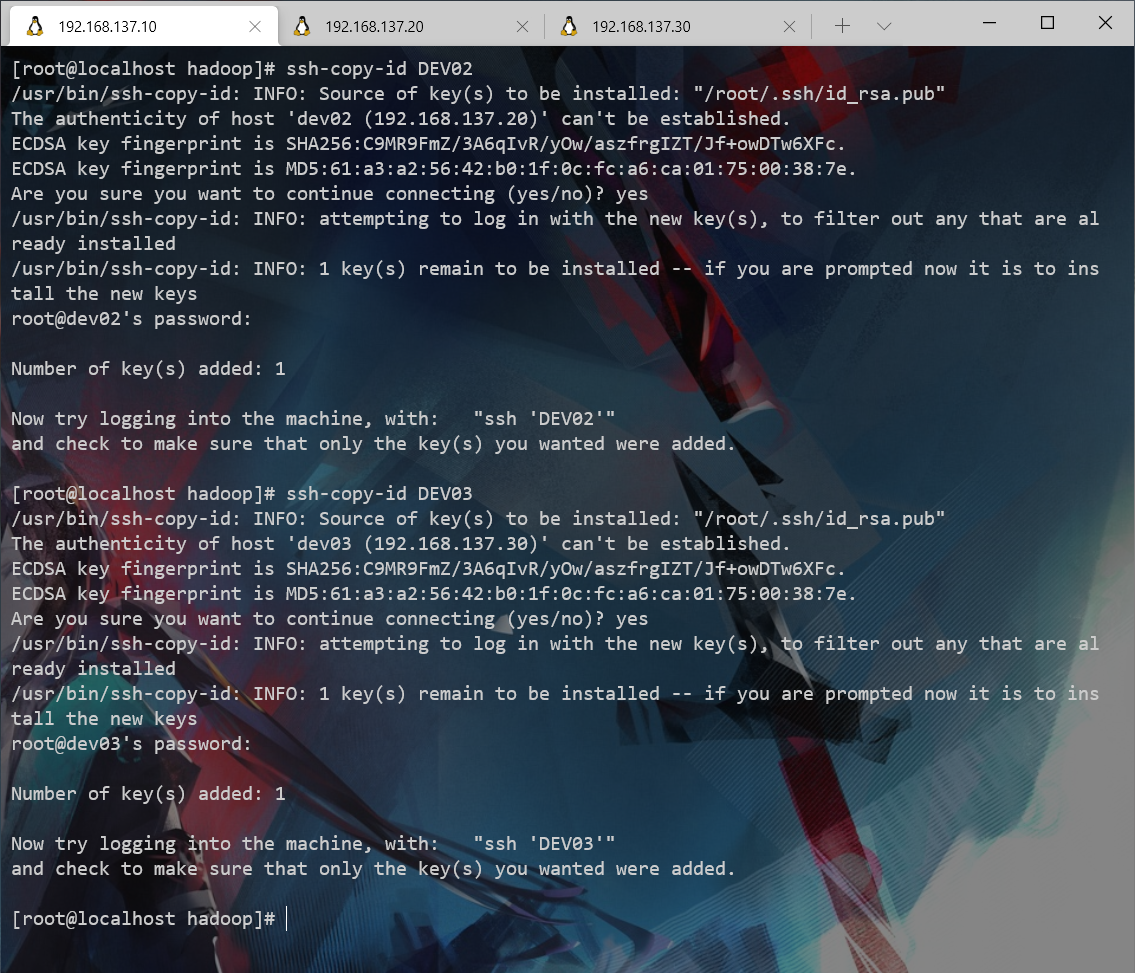
ssh-keygen -t rsa
ssh-copy-id DEV02
ssh-copy-id DEV03
cd .ssh/
touch authorized_keys
chmod 600 authorized_keys
cat id_rsa.pub >> authorized_keys
# DEV02
ssh-keygen -t rsa
ssh-copy-id DEV01
ssh-copy-id DEV03
cd .ssh/
touch authorized_keys
chmod 600 authorized_keys
cat id_rsa.pub >> authorized_keys
# DEV03
ssh-keygen -t rsa
ssh-copy-id DEV01
ssh-copy-id DEV02
cd .ssh/
touch authorized_keys
chmod 600 authorized_keys
cat id_rsa.pub >> authorized_keys
zookeeper
版本:apache-zookeeper-3.7.0-bin
新建配置 zoo.cfg
vim /home/soft/apache-zookeeper-3.7.0-bin/conf/zoo.cfg
添加内容:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/soft/apache-zookeeper-3.7.0-bin/zkData
dataLogDir=/home/soft/apache-zookeeper-3.7.0-bin/zkData/logs
clientPort=2181
server.1=192.168.137.10:2888:3888
server.2=192.168.137.20:2888:3888
server.3=192.168.137.30:2888:3888
创建文件夹并且将配置中的serverid 写入到myid文件
mkdir /home/soft/apache-zookeeper-3.7.0-bin/zkData
mkdir /home/soft/apache-zookeeper-3.7.0-bin/zkData/logs
echo 1 >> /home/soft/apache-zookeeper-3.7.0-bin/zkData/myid
cat myid
分发到 2、3号服务器上
scp -r /home/soft/apache-zookeeper-3.7.0-bin/ root@192.168.137.20:/home/soft/
scp -r /home/soft/apache-zookeeper-3.7.0-bin/ root@192.168.137.30:/home/soft/
修改分发过去的myid文件
sudo vim /home/soft/apache-zookeeper-3.7.0-bin/zkData/myid
验证 zookeeper 环境是否配置好
which zkCli.sh
/home/soft/apache-zookeeper-3.7.0-bin/bin/zkCli.sh

启动 zookeeper
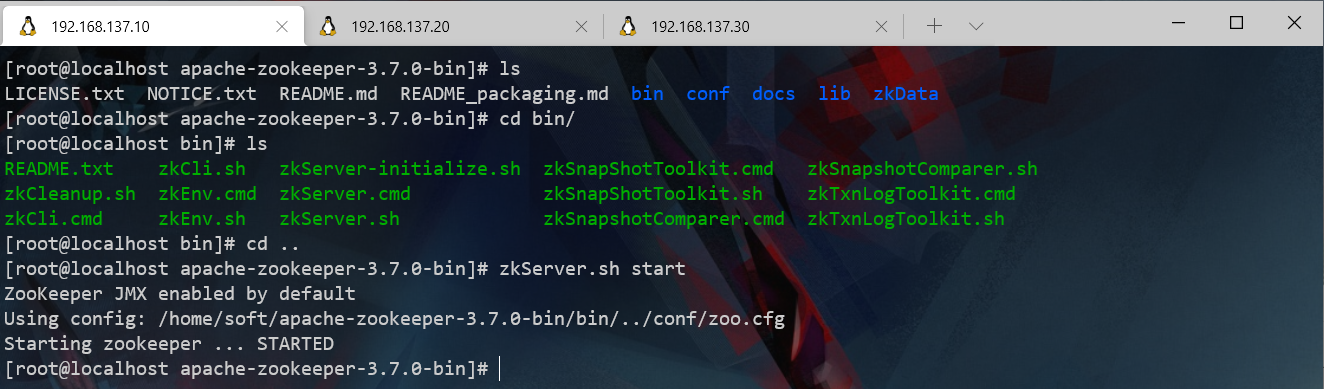
# 启动zk
zkServer.sh start
# jsp
1914 QuorumPeerMain
1949 Jps
# zk 连接
zkCli.sh
防火墙或其他问题处理
防火墙设置
出现如下错误情况,排查防火墙问题。上面并没有关闭防火墙。
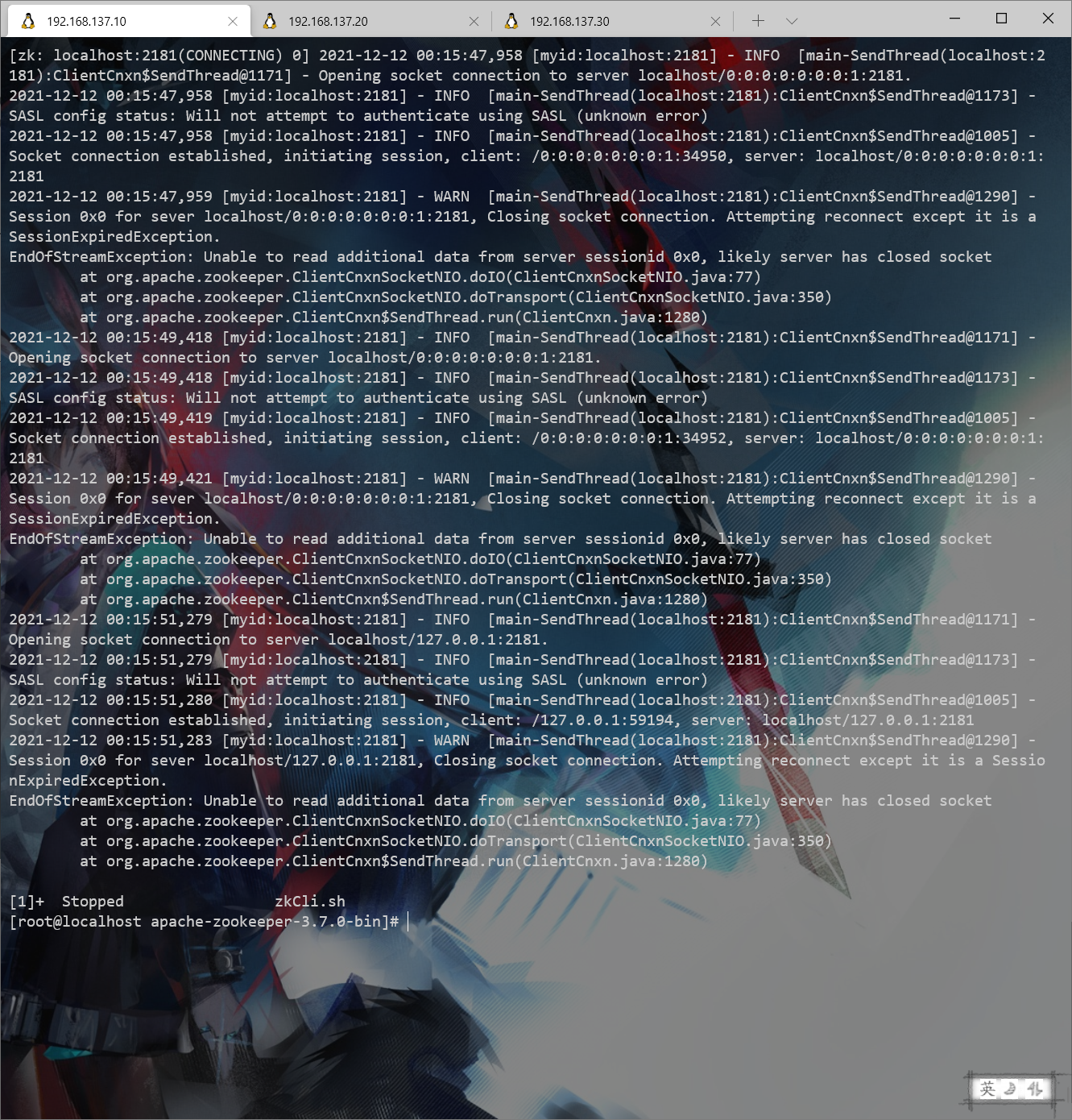
开启8080、2181、2888、3888端口并重启防火墙
[root@localhost bin]# firewall-cmd --zone=public --add-port=2181/tcp --permanent
success
[root@localhost bin]# firewall-cmd --zone=public --add-port=2888/tcp --permanent
success
[root@localhost bin]# firewall-cmd --zone=public --add-port=3888/tcp --permanent
success
[root@localhost ~]# firewall-cmd --zone=public --add-port=8080/tcp --permanent
success
[root@localhost bin]# systemctl restart firewalld.service
systemctl status firewalld 查看防火墙状态
systemctl stop firewalld 临时关闭防火墙
systemctl disable firewalld 彻底关闭防火墙
端口占用
查看端口的使用清况,移除进程或删除zkData下的pid文件
netstat -apn | grep 2181
# kill -9 pid
成功启动 zookeeper
[root@localhost ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/soft/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@localhost ~]#
# zk 连接
zkCli.sh
[zk: localhost:2181(CONNECTED) 2] ls /
[zookeeper]
hadoop
版本:hadoop-3.1.3
zk+hadoop
DEV01 DEV02 作为 namenode datanode
DEV03 作为datanode
概述
(1) 为什么会有Hadoop HA机制?
HA:High Available,高可用 在Hadoop 2.0之前,在HDFS集群中NameNode存在单点故障 (SPOF:A Single Point of Failure) 对于只有一个NameNode的集群,如果NameNode机器出现故障(比如宕机或是软件、硬件升级),那么整个集群将无法使用,直到NameNode重新启动
(2) 如何解决?
HDFS的HA功能通过配置Active/Standby两个NameNode 实现在集群中对NameNode的热备来解决上述问题。
如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
在一个典型的HDFS(HA)集群中,使用多台单独的机器配置为 NameNode,在任何时间点,确保多个NameNode中只有一个处于 Active状态,其他的处在Standby状态。
其中ActiveNameNode负责集群中的所有客户端操作,StandbyNameNode仅仅充当备机,保证一旦ActiveNameNode出现问题能够快速切换。
为了能够实时同步Active和Standby两个NameNode的元数据信息(editlog),需提供一个共享存储系统,可以是NFS、QJM(Quorum Journal Manager)或者Zookeeper,ActiveNamenode将数据写入共享存储系统,而Standby监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与 ActiveNameNode保持基本一致,如此这般,在紧急情况下 standby便可快速切为 activenamenode。
为了实现快速切换,Standby节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标,DataNode需要配置所有NameNode的位置,并同时给他们发送文件块信息以及心跳检测。
| 主机名 | ip | NameNode | DataNode | Yarn | ZooKeeper | JournalNode |
|---|---|---|---|---|---|---|
| DEV01 | 192.168.137.10 | 是 | 是 | 是 | 是 | 是 |
| DEV02 | 192.168.137.20 | 是 | 是 | 是 | 是 | 是 |
| DEV03 | 192.168.137.30 | 否 | 是 | 否 | 是 | 否 |
关键文件配置
hadoop version
cd /home/soft/hadoop-3.1.3/etc/hadoop/
| FILE | DESC |
|---|---|
| hadoop-env.sh | 脚本中要用到的环境变量,以运行hadoop |
| mapred-env.sh | 脚本中要用到的环境变量,以运行mapreduce(覆盖hadoop-env.sh中设置的变量) |
| yarn-env.sh | 脚本中要用到的环境变量,以运行YARN(覆盖hadoop-env.sh中设置的变量) |
| core.site.xml | Hadoop Core的配置项,例如HDFS,MAPREDUCE,YARN中常用的I/O设置等 |
| hdfs-site.xml | Hadoop守护进程的配置项,包括namenode和datanode等 |
| mapred-site.xml | MapReduce守护进程的配置项,包括job历史服务器 |
| yarn-site.xml | Yarn守护进程的配置项,包括资源管理器和节点管理器 |
| workers | 具体运行datanode和节点管理器的主机名称 |
hadoop-env.sh
# sudo vim hadoop-env.sh 添加如下内容
export JAVA_HOME=/home/soft/jdk1.8
export HADOOP_PID_DIR=/home/soft/hadoop-3.1.3/pids
export HADOOP_LOG_DIR=/home/soft/hadoop-3.1.3/logs
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
core-site.xml
<!--ns1可随意-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/files/hadoop-files/temp/</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>DEV01:2181,DEV02:2181,DEV03:2181</value>
</property>
hdfs-site.xml
<!-- namenode and datanode path -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/files/hadoop-files/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/files/hadoop-files/dfs/data</value>
</property>
<!-- webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!--
hdfs's nameservice as core-site.xml's nameservice
dfs.ha.namenodes.[nameservice id] is nameservice each NameNode id。
-->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!--ns1 nn1 and nn2-->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 RPC -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>DEV01:9000</value>
</property>
<!-- nn1 http -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>DEV01:50070</value>
</property>
<!-- nn2 RPC -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>DEV02:9000</value>
</property>
<!-- nn2 http -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>DEV02:50070</value>
</property>
<!-- NameNode's metadate JournalNode URI -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://DEV01:8485;DEV02:8485/ns1</value>
</property>
<!-- JournalNode path need do create -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/files/hadoop-files/journaldata</value>
</property>
<!-- NameNode automatic-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- ha active -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- ssh -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- run mapreduce -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>DEV01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>DEV02</value>
</property>
<!--ResourceManager - ApplicationMaster addr -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>DEV01:8030</value>
</property>
<!-- RM HTTP addr-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>DEV01:8088</value>
</property>
<!-- NodeManager addr -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>DEV01:8031</value>
</property>
<!-- admin -rm -->
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>DEV01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>DEV01:23142</value>
</property>
<!-- rm2 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>DEV02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>DEV02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>DEV02:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>DEV02:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>DEV02:23142</value>
</property>
<!-- zk -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>DEV01:2181,DEV02:2181,DEV03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
workers
sudo vim workers
# remove loclhost add
DEV01
DEV02
DEV03
分发到各个服务器
scp -r /home/soft/hadoop-3.1.3/ DEV02:/home/soft/
scp -r /home/soft/hadoop-3.1.3/ DEV03:/home/soft/
创建配置中的文件夹
mkdir -p /home/files/hadoop-files/journaldata
mkdir -p /home/files/hadoop-files/temp
tree /home/files/hadoop-files/
启动步骤
# 确认zk已经启动
zkServer.sh status
# 1.启动 jnnode
# DEV01 and DEV02
hdfs --daemon start journalnode
# 2.DEV01(active namenode)
hdfs namenode -format
hdfs zkfc -formatZK
hdfs --daemon start namenode
# 3.DEV02(Standby namenode)
# 等待DEV01启动namenode后执行,不然会出错(name 同步不过来)
hdfs namenode -bootstrapStandby
# 可查看dfs下有没有生成name文件夹
# 上述都操作完DEV01执行 stop-all.sh
stop-all.sh
# 上述都操作完DEV01执行 start-all.sh
start-all.sh
一些错误及解决方法
hdfs namenode -bootstrapStandby 错误
查看 DEV01 name 是否存在,DEV01 jps 进程是否已经有namenode,没有需要启动后 ( hdfs --daemon start namenode)
DEV02 再执行:hdfs namenode -bootstrapStandby

启动错误
ssh免密是否全部在每个服务器上配置完毕(自身ssh自身也要配置)
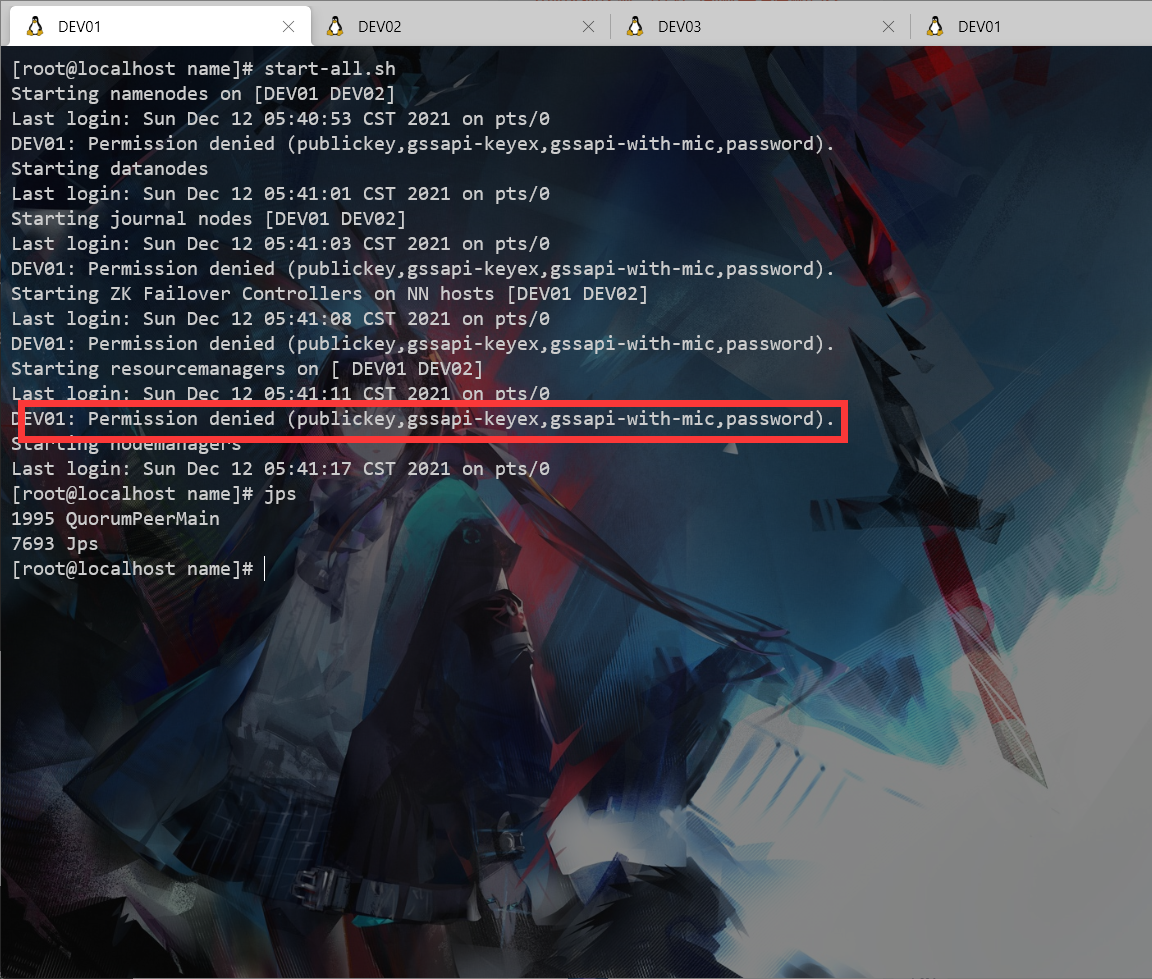
# ssh DEV01
[root@localhost ~]# cd .ssh/
[root@localhost .ssh]# ls
id_rsa id_rsa.pub known_hosts
[root@localhost .ssh]# touch authorized_keys
[root@localhost .ssh]# ls
authorized_keys id_rsa id_rsa.pub known_hosts
[root@localhost .ssh]# chmod 600 authorized_keys
[root@localhost .ssh]# cat id_rsa.pub >> authorized_keys
[root@localhost .ssh]# ssh DEV01
Last login: Sun Dec 12 05:45:34 2021 from dev03
[root@localhost ~]#
webUI只显示一个datanodes,但是datanode都存活
# 查看hdfs-site.xml 里设置的data位置
cd /home/files/hadoop-files/dfs/data/current/
ls
BP-1707627147-127.0.0.1-1639257881620 VERSION
rm -f VERSION
重新初始化或者改一下VERSION里的
datanodeUuid=63f64db4-3907-494d-858f-34a6813521cf
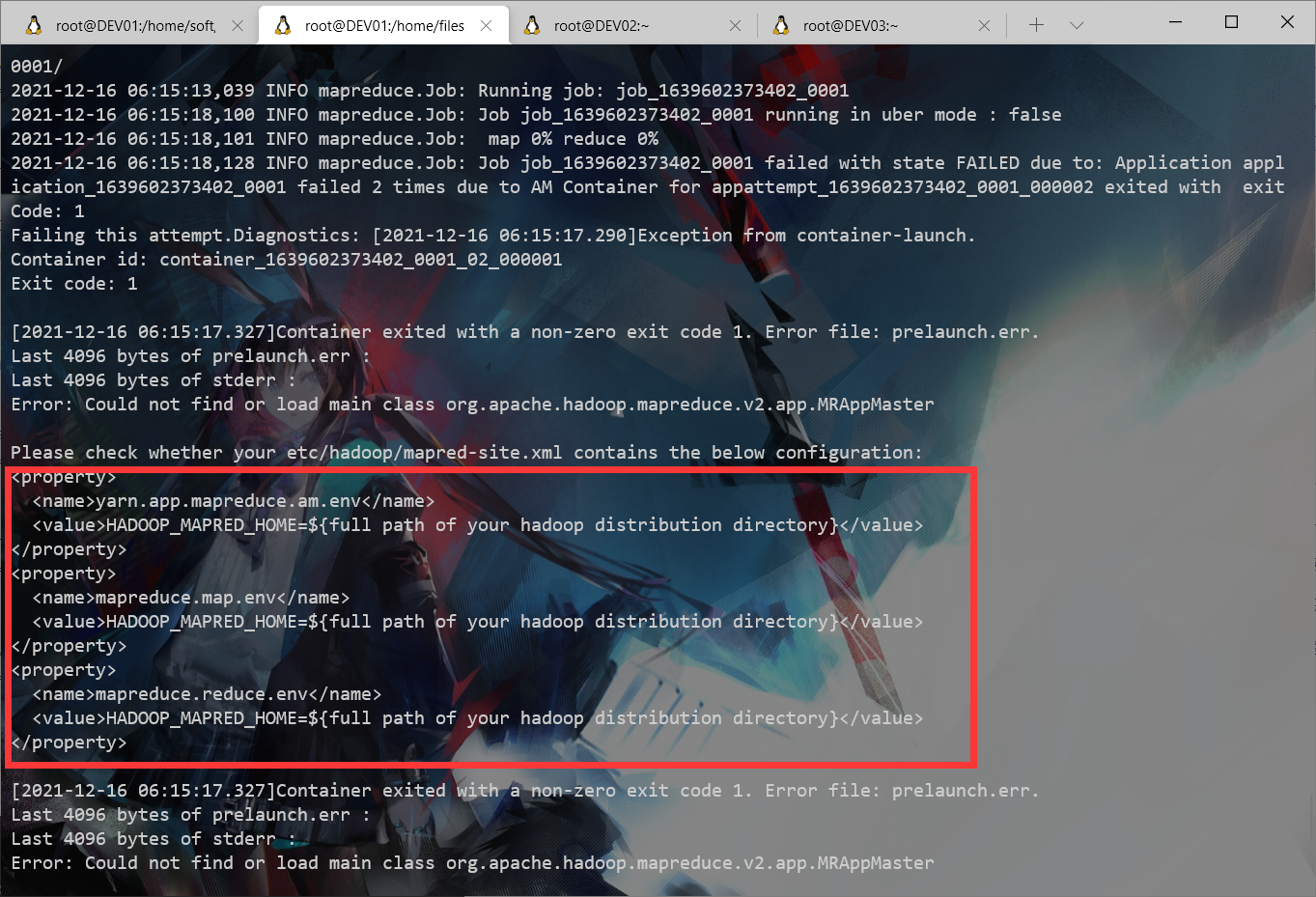
执行MapReduce失败以及RM的通信问题
#添加如提示中的配置:
sudo vim mapred-site.xml
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
sudo vim yarn-site.xml
<!--ResourceManager - ApplicationMaster addr -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>DEV01:8030</value>
</property>
<!-- RM HTTP addr-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>DEV01:8088</value>
</property>
<!-- NodeManager addr -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>DEV01:8031</value>
</property>
<!-- admin -rm -->
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>DEV01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>DEV01:23142</value>
</property>
<!-- rm2 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>DEV02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>DEV02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>DEV02:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>DEV02:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>DEV02:23142</value>
</property>
# check
yarn rmadmin -getServiceState rm1
active
yarn rmadmin -getServiceState rm2
standby
完成
# DEV01
start-all.sh
# jps 查看各个服务器进程
# DEV01(7) DEV02(7) DEV03(3)
jps
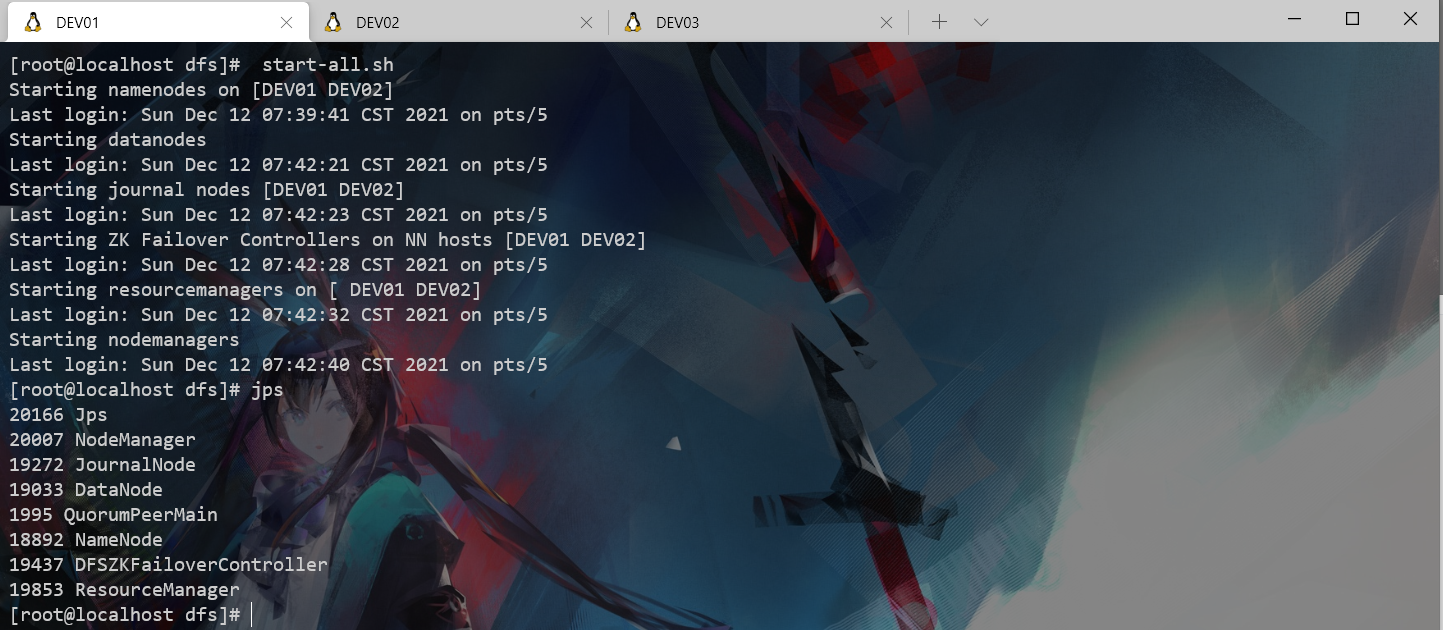
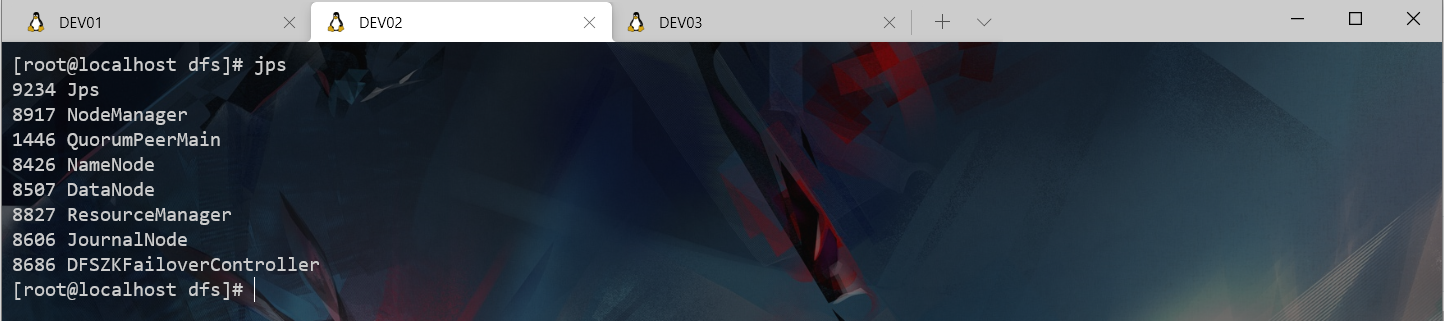

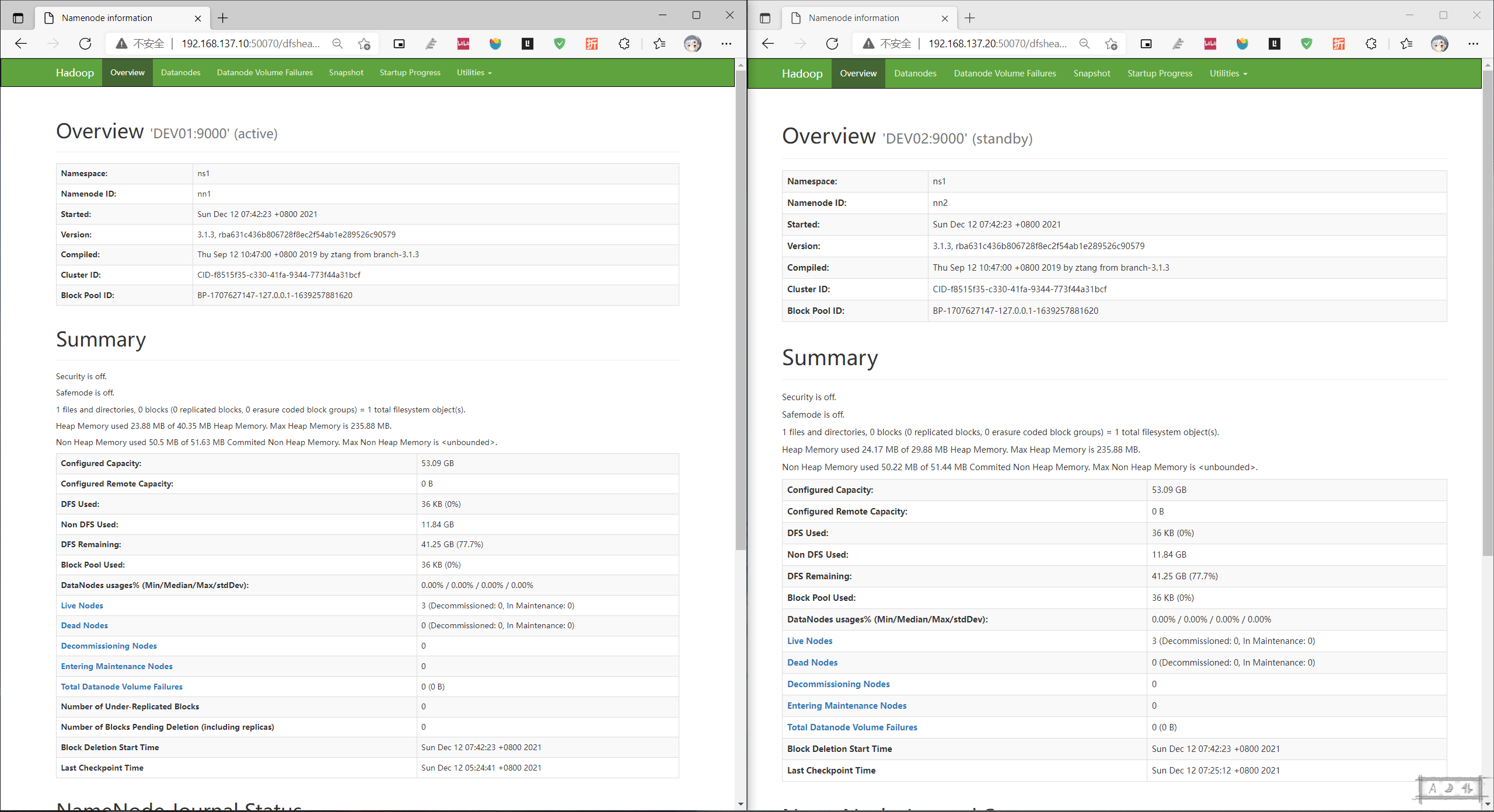
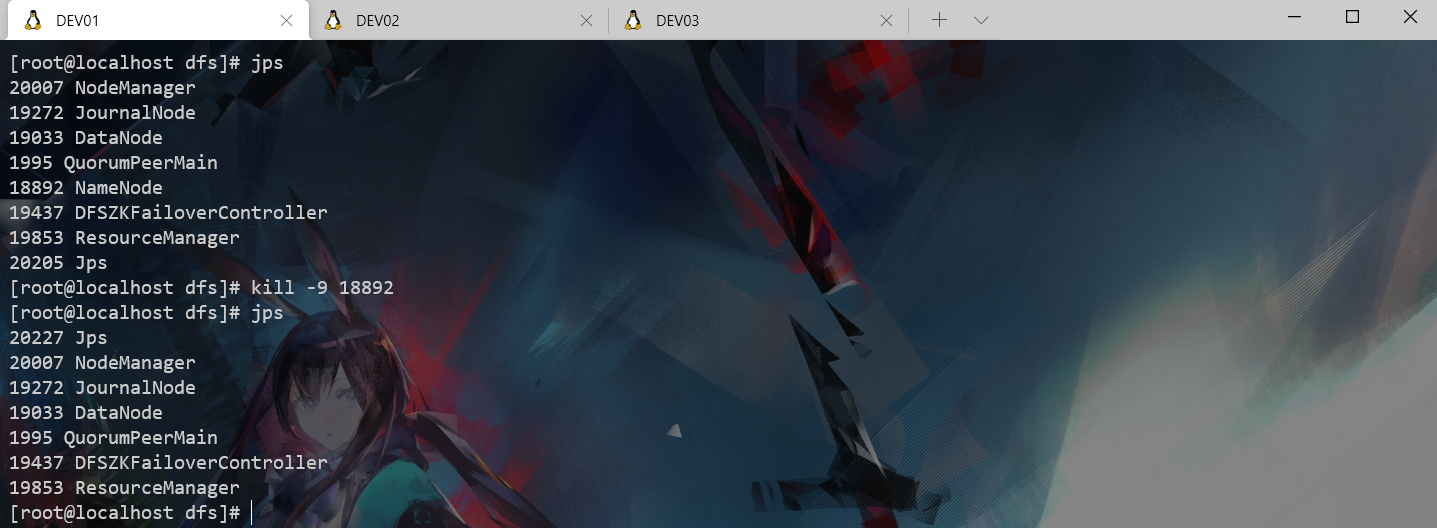
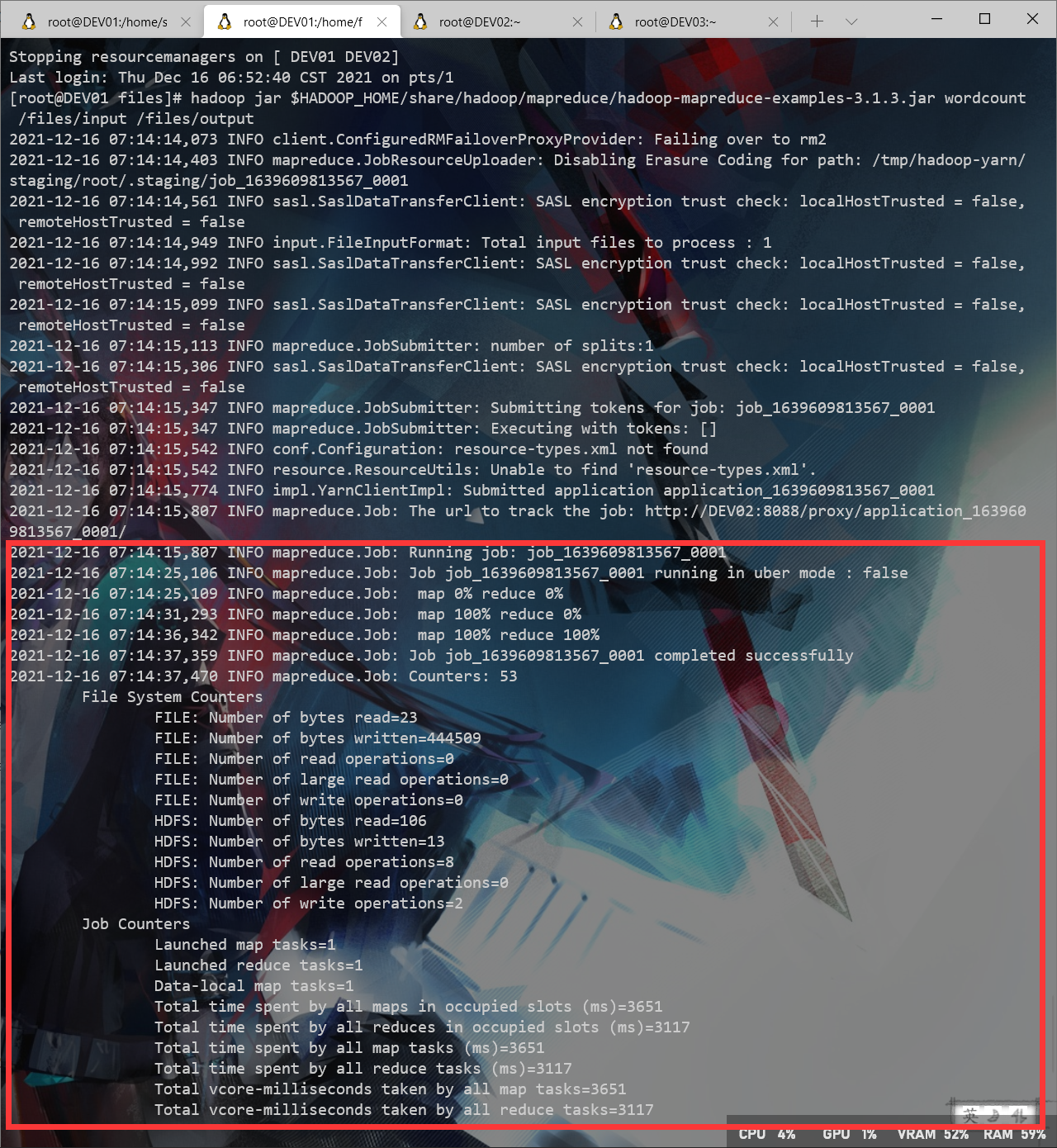
kill 了DEV01的进程后DEV02变成了active,基于zookeeper的Hadoop HA高可用集群搭建完成并验证HA有效。
(单独再次启动DEV01的NameNode后DEV01状态’DEV01:9000’ (standby))
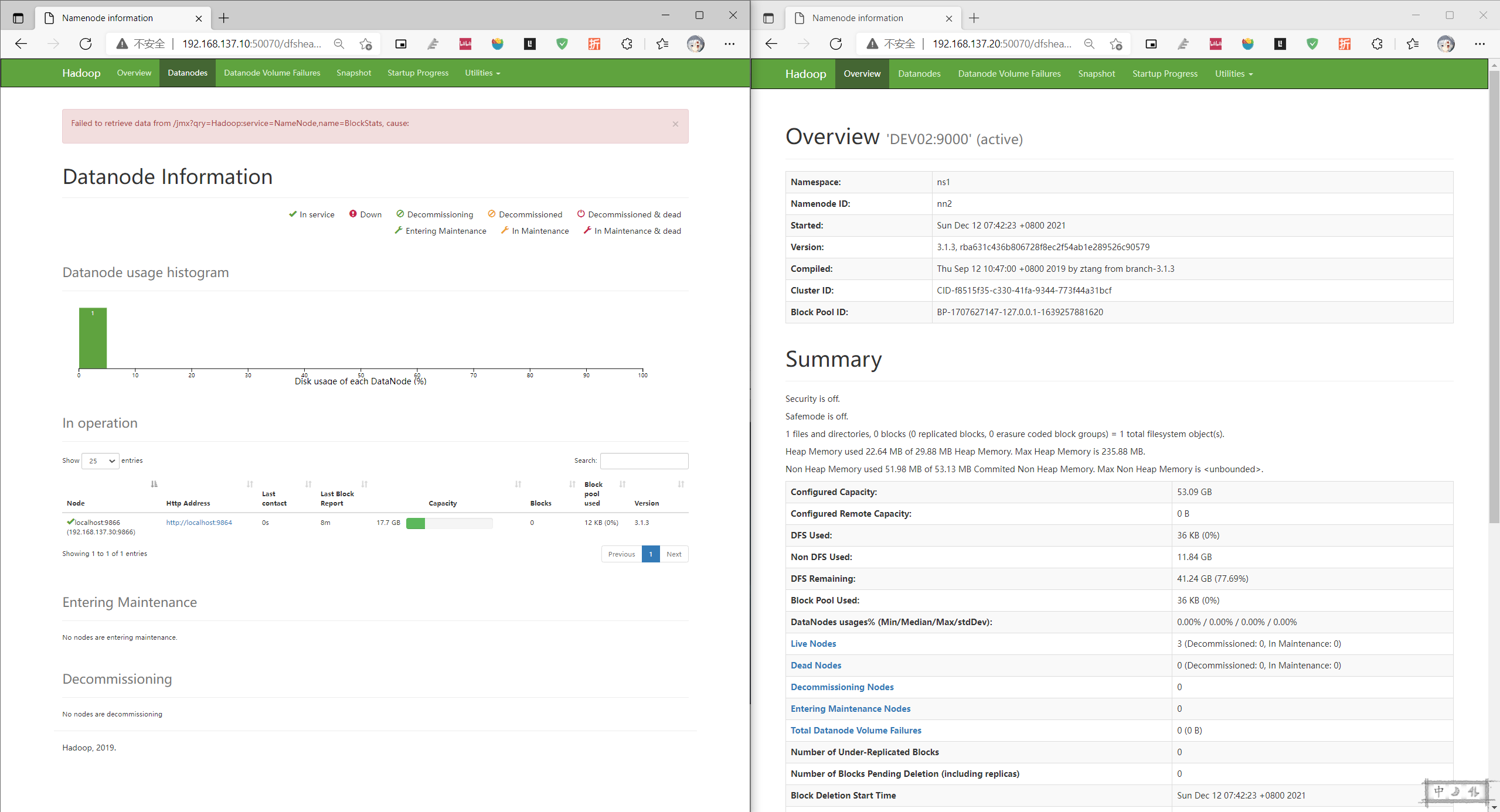
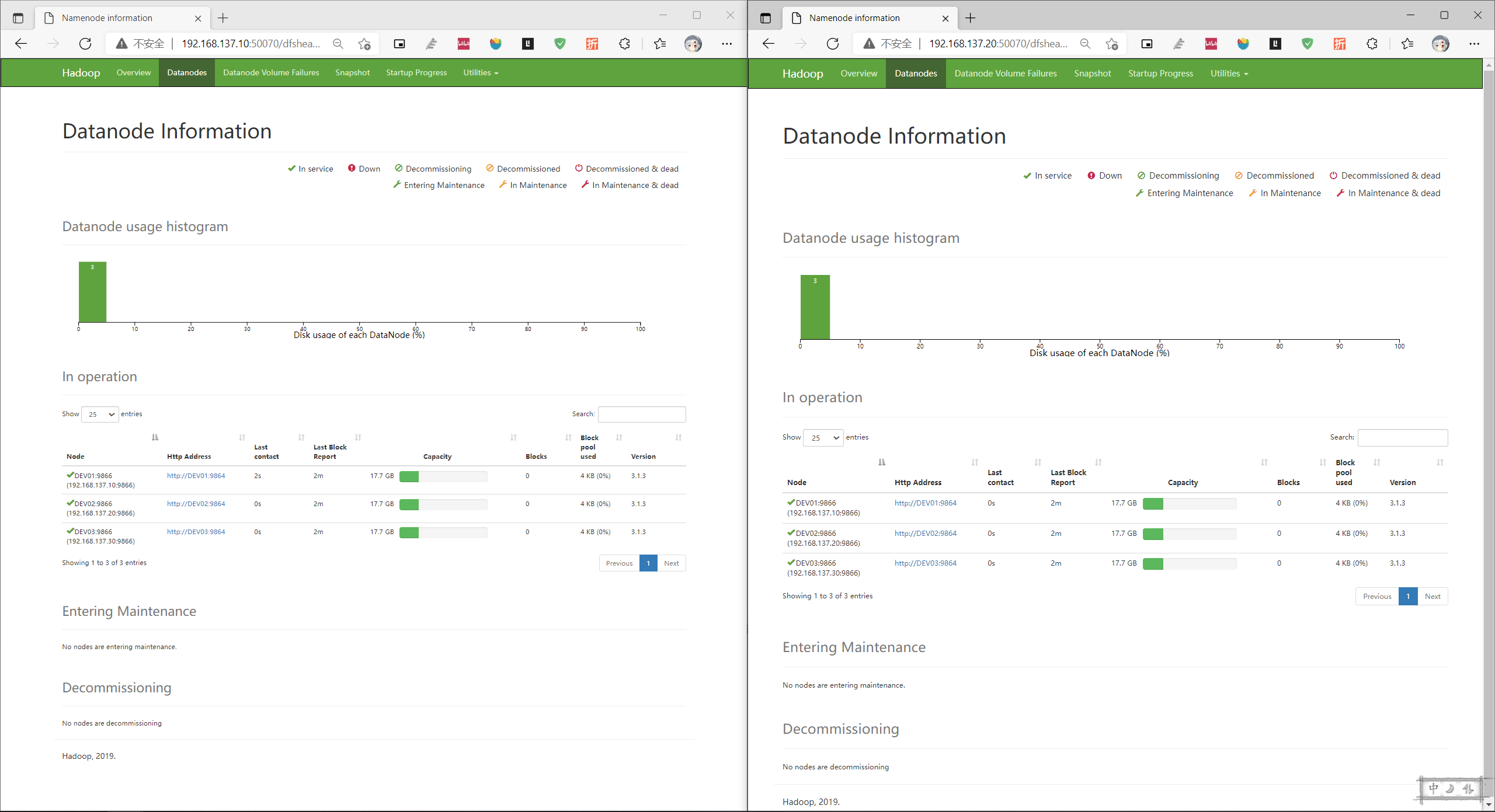
只能访问active的节点
END
基于ZK的HADOOP HA 搭建完毕。

